数据导入
1、将msyql数据导入值es中
经测试比较适合百万级别的,再大需要按照某一个字段拆分用多进程的方式跑
import pymysql.cursors
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import configUtil
import fieldConfig
schema = configUtil.schema
tableList = configUtil.table_list
connect = pymysql.Connect(
host=configUtil.dbHost,
port=configUtil.dbPort,
user=configUtil.dbUser,
passwd=configUtil.dbPassword,
db=schema,
charset='utf8'
)
cursor = connect.cursor()
pageSize = 1000
es = Elasticsearch(
[configUtil.esUrl],
# 认证信息
# http_auth=(configUtil.esUser, configUtil.esPassword)
)
def getFields(schema, tableName):
sql = """
select aa.COLUMN_NAME,aa.DATA_TYPE,aa.COLUMN_COMMENT, cc.TABLE_COMMENT
from information_schema.`COLUMNS` aa LEFT JOIN
(select DISTINCT bb.TABLE_SCHEMA,bb.TABLE_NAME,bb.TABLE_COMMENT
from information_schema.`TABLES` bb ) cc
ON (aa.TABLE_SCHEMA=cc.TABLE_SCHEMA and aa.TABLE_NAME = cc.TABLE_NAME )
where aa.TABLE_SCHEMA = '%s' and aa.TABLE_NAME = '%s'
"""
data = (schema, tableName,)
cursor.execute(sql % data)
fields = {}
for row in cursor.fetchall():
temp = {}
temp['name'] = str(row[0])
temp['type'] = str(row[1])
fields[temp['name']] = temp
return fields
def getMaxId(tableName):
query = {
"query": {
"match_all": {}
},
"sort": [
{
"id": {
"order": "desc"
}
}
],
}
result = es.search(index=tableName, size=1, body=query)
if int(result['hits']['total']['value']) > 0:
return int(result['hits']['hits'][0]['_source']['id'])
return 0
def countTable(tableName):
query = {
"query": {
"match_all": {}
},
"sort": [
{
"id": {
"order": "desc"
}
}
],
}
result = es.search(index=tableName, size=1, body=query)
return int(result['hits']['total']['value'])
def runData(tableName):
fields = getFields(schema, tableName)
index = getMaxId(tableName)
count = countTable(tableName)
sql = 'select * from %s where id > %d order by id limit %d '
while True:
param = (tableName, index, pageSize,)
cursor.execute(sql % param)
insertDatas = []
columns = []
for column in cursor.description:
columns.append(column[0])
for row in cursor.fetchall():
tempData = {}
for i in range(0, len(columns)):
column = columns[i]
value = row[i]
if column == 'id':
index = int(value)
tempData[column] = fieldConfig.convert_data_from_es_to_python(value, fields[column]['type'])
insertDatas.append(tempData)
actions = []
for tempData in insertDatas:
action = {
"_index": tableName,
"_source": tempData,
"_id": tempData['id']
}
actions.append(action)
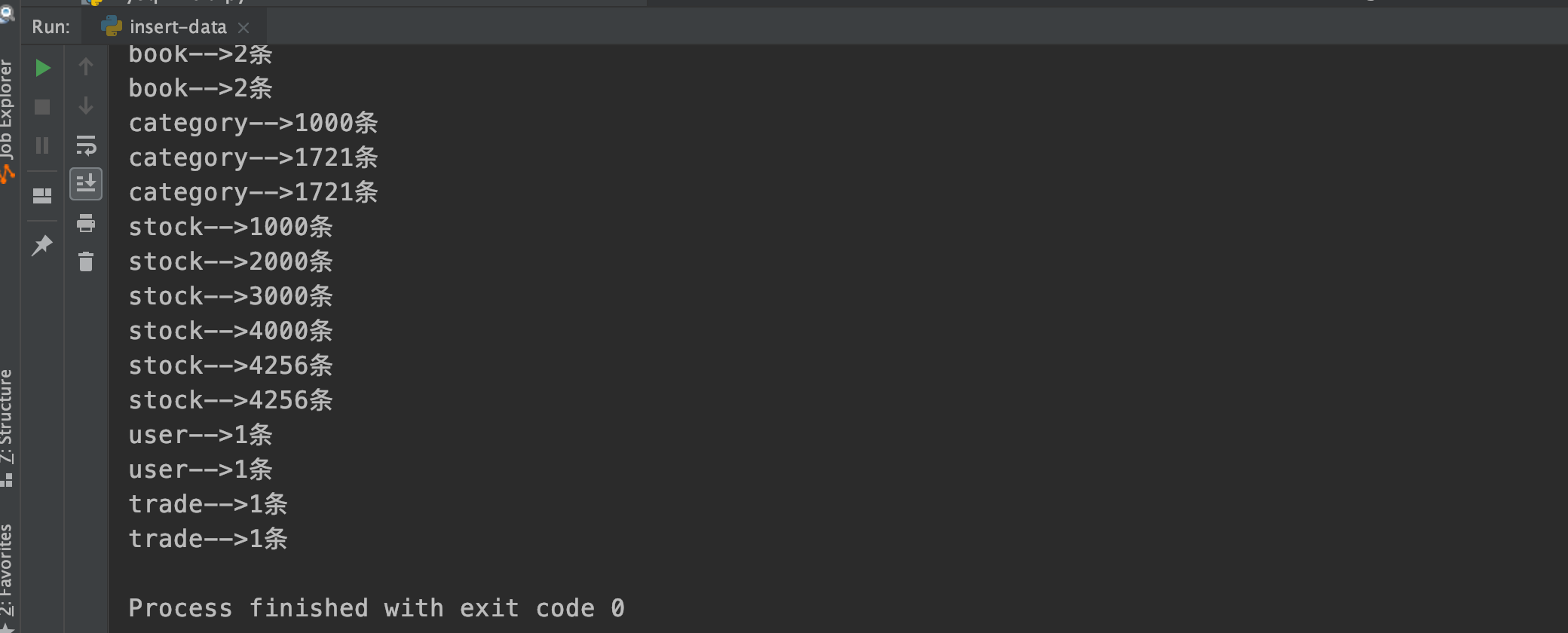
count = count + 1
print(tableName + "-->" + str(count) + "条")
helpers.bulk(es, actions)
if len(insertDatas) <= 0:
break
if __name__ == '__main__':
for tableName in tableList:
runData(tableName)
2、校验以及补偿:
按照id比对,检验数据导入有无遗漏,遗漏需找出id进行补偿
import pymysql.cursors
from elasticsearch import Elasticsearch
from elasticsearch import helpers
import configUtil
import fieldConfig
es = Elasticsearch(
[configUtil.esUrl],
# 认证信息
# http_auth=(configUtil.esUser, configUtil.esPassword)
)
schema = configUtil.schema
tableList = configUtil.table_list
connect = pymysql.Connect(
host=configUtil.dbHost,
port=configUtil.dbPort,
user=configUtil.dbUser,
passwd=configUtil.dbPassword,
db=schema,
charset='utf8'
)
cursor = connect.cursor()
def deleteEs(tableName, idList):
print("删除多余id:" + str(idList))
start = 0
size = 100
while start < len(idList):
tempList = idList[start:start + size]
if len(tempList) <= 0:
break
deleteQuery = {
"query": {
"bool": {
"must": [
{
"ids": {
"values": tempList
}
}
]
}
}
}
es.delete_by_query(index=tableName, body=deleteQuery)
start = start + size
def countAllES(tableName):
query = {
"query": {
"match_all": {}
}
}
result = es.search(index=tableName, size=1, body=query)
return int(result['hits']['total']['value'])
def showIndexs():
print(es.indices.get_alias().keys())
def countEsWithProject(tableName, projectId):
query = {
"query": {
"term": {
"projectId": projectId,
}
},
}
result = es.search(index=tableName, size=1, body=query)
return int(result['hits']['total'])
def queryAllIdWithProject(tableName):
esIdList = []
query = {
"query": {
"match_all": {}
},
"_source": {
"excludes": ["*"]
}
}
result = es.search(index=tableName, size=5000, body=query, scroll="1m")
while True:
scrollId = result['_scroll_id']
size = int(len(result['hits']['hits']))
if size > 0:
for hit in result['hits']['hits']:
esIdList.append(int(hit['_id']))
result = es.scroll(scroll_id=scrollId, scroll="1m")
else:
break
return esIdList
def countAllTable(tableName):
sql = "select count(*) from %s"
cursor.execute(sql % (tableName,))
result = 0
for row in cursor.fetchall():
result = int(row[0])
break
return result
def countTableWithProject(tableName, projectId):
sql = "select count(*) from %s where projectId = %d"
cursor.execute(sql % (tableName, projectId))
result = 0
for row in cursor.fetchall():
result = int(row[0])
break
return result
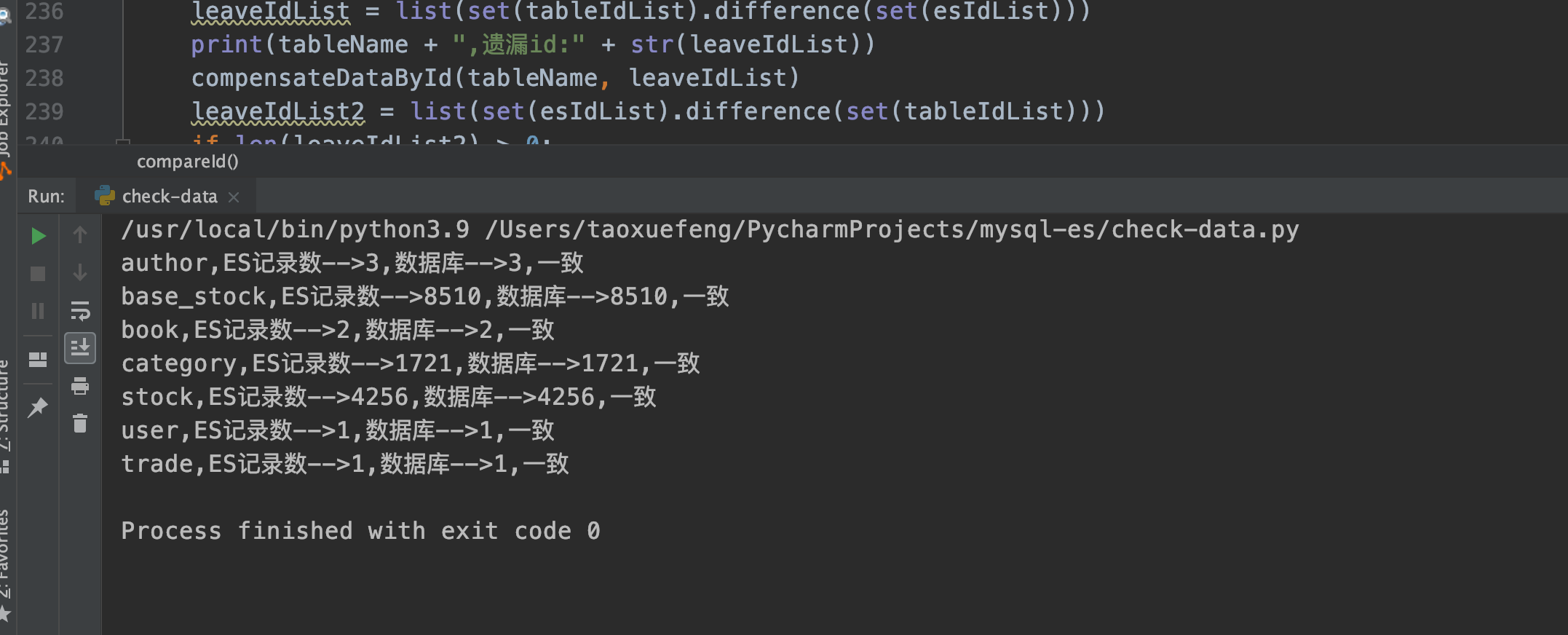
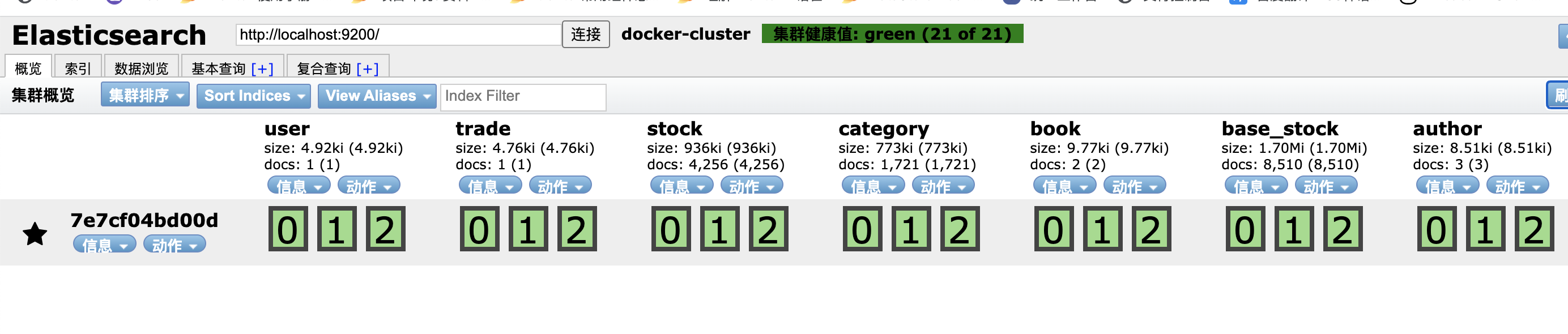
def countAll():
for tableName in tableList:
len1 = countAllES(tableName)
len2 = countAllTable(tableName)
if len1 == len2:
print(tableName + ",ES记录数-->" + str(len1) + ",数据库-->" + str(len2) + ",一致")
else:
print(tableName + ",ES记录数-->" + str(len1) + ",数据库-->" + str(len2) + ",不一致")
def compensateAll():
for tableName in tableList:
len1 = countAllES(tableName)
len2 = countAllTable(tableName)
if len1 == len2:
print(tableName + ",ES记录数-->" + str(len1) + ",数据库-->" + str(len2) + ",一致")
else:
print(tableName + ",ES记录数-->" + str(len1) + ",数据库-->" + str(len2) + ",不一致")
compareId(tableName)
def queryAllProject():
sql = "select id from sm_project__project"
cursor.execute(sql)
projectIdList = []
for row in cursor.fetchall():
projectIdList.append(int(row[0]))
return projectIdList
def getFields(schema, tableName):
sql = """
select aa.COLUMN_NAME,aa.DATA_TYPE,aa.COLUMN_COMMENT, cc.TABLE_COMMENT
from information_schema.`COLUMNS` aa LEFT JOIN
(select DISTINCT bb.TABLE_SCHEMA,bb.TABLE_NAME,bb.TABLE_COMMENT
from information_schema.`TABLES` bb ) cc
ON (aa.TABLE_SCHEMA=cc.TABLE_SCHEMA and aa.TABLE_NAME = cc.TABLE_NAME )
where aa.TABLE_SCHEMA = '%s' and aa.TABLE_NAME = '%s'
"""
data = (schema, tableName,)
cursor.execute(sql % data)
fields = {}
for row in cursor.fetchall():
temp = {}
temp['name'] = str(row[0])
temp['type'] = str(row[1])
fields[temp['name']] = temp
return fields
def splitIdList(idList, size):
idListList = []
num = len(idList)
left = 0
right = left + size
while True:
if left >= num:
break
else:
idListList.append(idList[left:right])
left = right
right = left + size
return idListList
def compensateDataById(tableName, idList):
count = 0
fields = getFields(schema, tableName)
idListList = splitIdList(idList, 100)
for idList in idListList:
idstr = ''
for i in range(0, len(idList)):
if i < len(idList) - 1:
idstr += str(idList[i])
idstr += ','
else:
idstr += str(idList[i])
sql = 'select * from %s where id in (%s)'
param = (tableName, idstr)
cursor.execute(sql % param)
insertDatas = []
columns = []
for column in cursor.description:
columns.append(column[0])
for row in cursor.fetchall():
tempData = {}
for i in range(0, len(columns)):
column = columns[i]
value = row[i]
tempData[column] = fieldConfig.convert_data_from_es_to_python(value, fields[column]['type'])
insertDatas.append(tempData)
actions = []
for tempData in insertDatas:
action = {
"_index": tableName,
"_source": tempData,
"_id": tempData['id']
}
actions.append(action)
count = count + 1
helpers.bulk(es, actions)
print(tableName + ", 补偿数据 " + str(count))
def compareId(tableName):
sql = "select id from %s"
cursor.execute(sql % (tableName,))
tableIdList = []
for row in cursor.fetchall():
tableIdList.append(int(row[0]))
esIdList = queryAllIdWithProject(tableName)
leaveIdList = list(set(tableIdList).difference(set(esIdList)))
print(tableName + ",遗漏id:" + str(leaveIdList))
compensateDataById(tableName, leaveIdList)
leaveIdList2 = list(set(esIdList).difference(set(tableIdList)))
if len(leaveIdList2) > 0:
print(tableName + ",多余id" + str(leaveIdList2))
deleteEs(tableName, leaveIdList2)
if __name__ == '__main__':
# showIndexs()
# countAll()
compensateAll()