Python Selenium天猫商品爬取(上)
首先,先对爬取的进行分类,主要根据下方这幅图的标注。
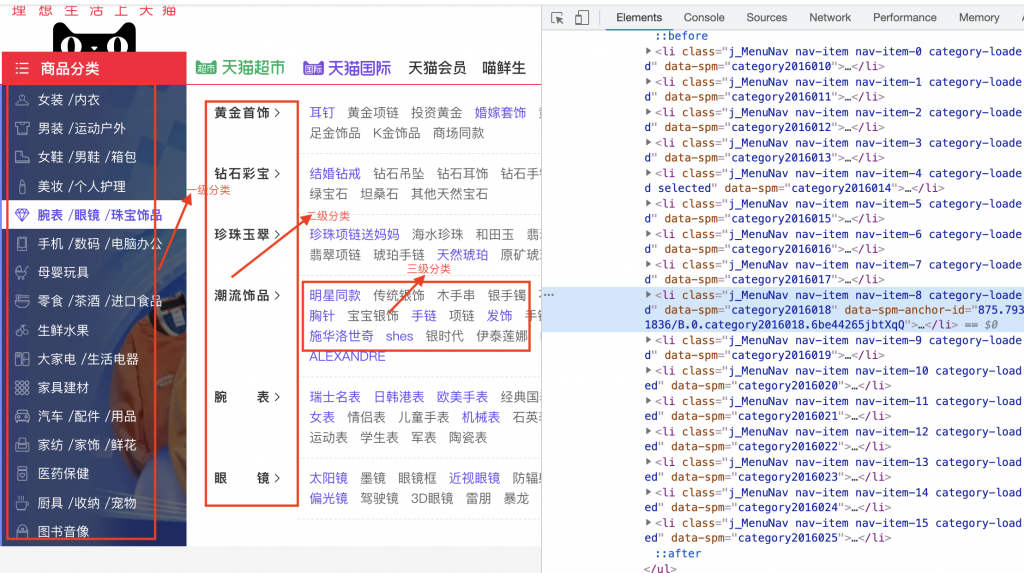
主要流程如下:
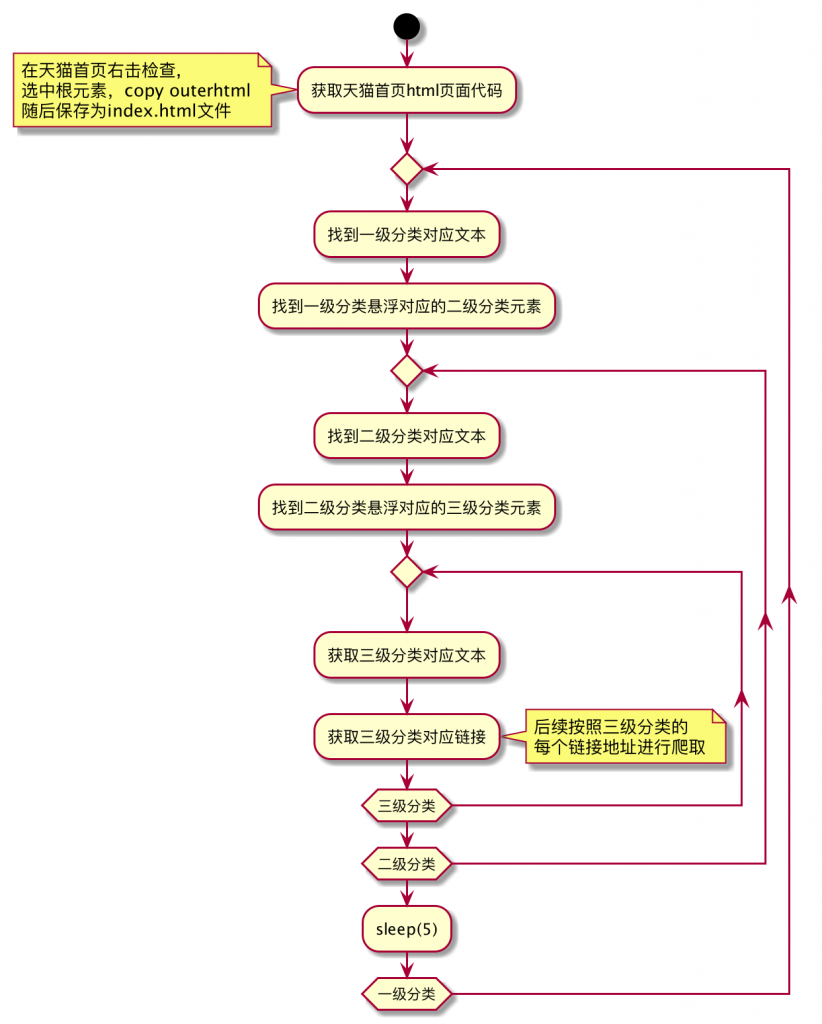
核心代码如下:
import json
import pymysql
from lxml import etree
connect = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='XXXXXXXXXX',
db='test',
charset='utf8'
)
cursor = connect.cursor()
def insert(name, level, parentId, url):
if parentId is None:
sql = "insert into category(name,level) values('%s',%d);"
sql = sql % (name, level)
else:
if url is None:
sql = "insert into category(name,level,parent_id) values('%s',%d,%d);"
sql = sql % (name, level, parentId)
else:
sql = "insert into category(name,level,parent_id,url) values('%s',%d,%d,'%s');"
sql = sql % (name, level, parentId, url)
print(sql)
cursor.execute(sql)
current_id = connect.insert_id()
connect.commit()
return current_id
def getContent(ele):
result = ""
if isinstance(ele, list):
for i in range(0, len(ele)):
item = ele[i]
result = result + item.encode("ISO-8859-1").decode("utf-8")
if i < len(ele) - 1:
result = result + "/"
else:
result = ele.encode("ISO-8859-1").decode("utf-8")
return result
html = etree.parse("index.html", etree.HTMLParser())
first = html.xpath("//*[@id='content']/div[2]/div[1]/div[2]/div[1]/ul/li")
categoryList = []
for temp in first:
ele = temp.xpath("./a/text()")
item = {}
item['name'] = getContent(ele)
categoryList.append(item)
second = html.xpath("//*[@id='content']/div[2]/div[1]/div[3]/div")
index = 0
for item_second in second:
third = item_second.xpath("./div/div[1]/div")
secondList = []
for item_third in third:
item = {}
p = item_third.xpath("./div[1]/div/text()")
item['name'] = getContent(p)
item_third_detail = item_third.xpath("./div[2]/a")
thirdList = []
for item_detail in item_third_detail:
temp_detail = {}
temp_detail["url"] = str(item_detail.xpath("./@href")[0]).replace("'", "")
temp_detail['name'] = getContent(item_detail.xpath("./text()"))
thirdList.append(temp_detail)
item['third'] = thirdList
secondList.append(item)
categoryList[index]['second'] = secondList
index = index + 1
print(json.dumps(categoryList, ensure_ascii=False))
for cate in categoryList:
firstId = insert(cate['name'], 1, None, None)
for temp in cate['second']:
secondId = insert(temp['name'], 2, firstId, None)
for temp2 in temp['third']:
insert(temp2['name'], 3, secondId, temp2['url'])
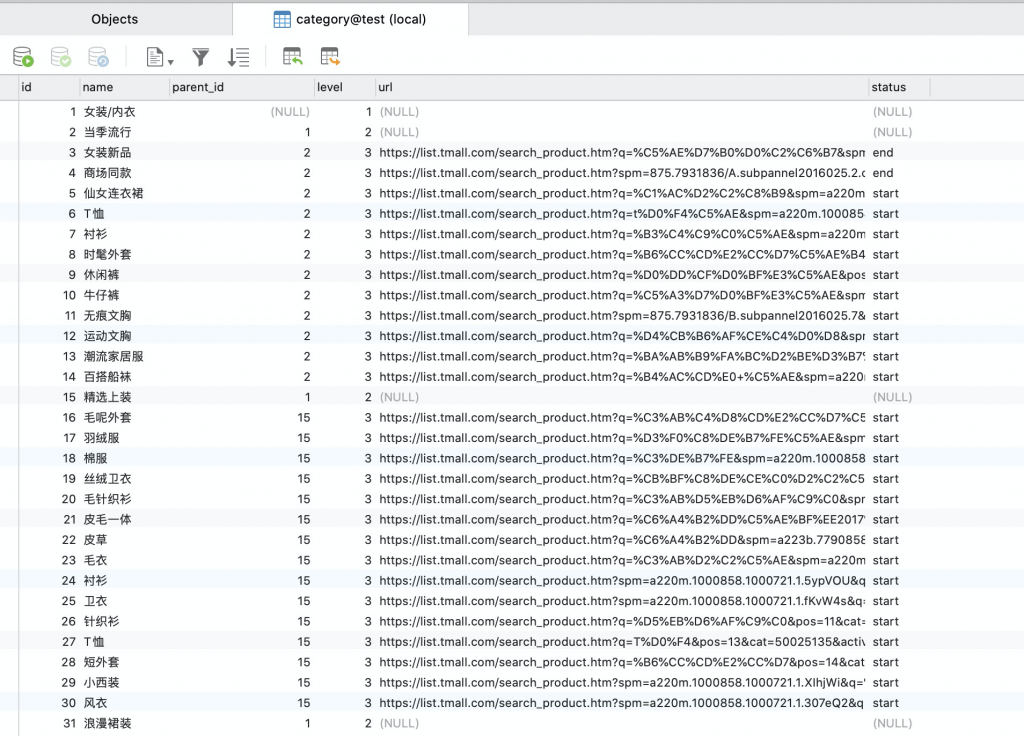
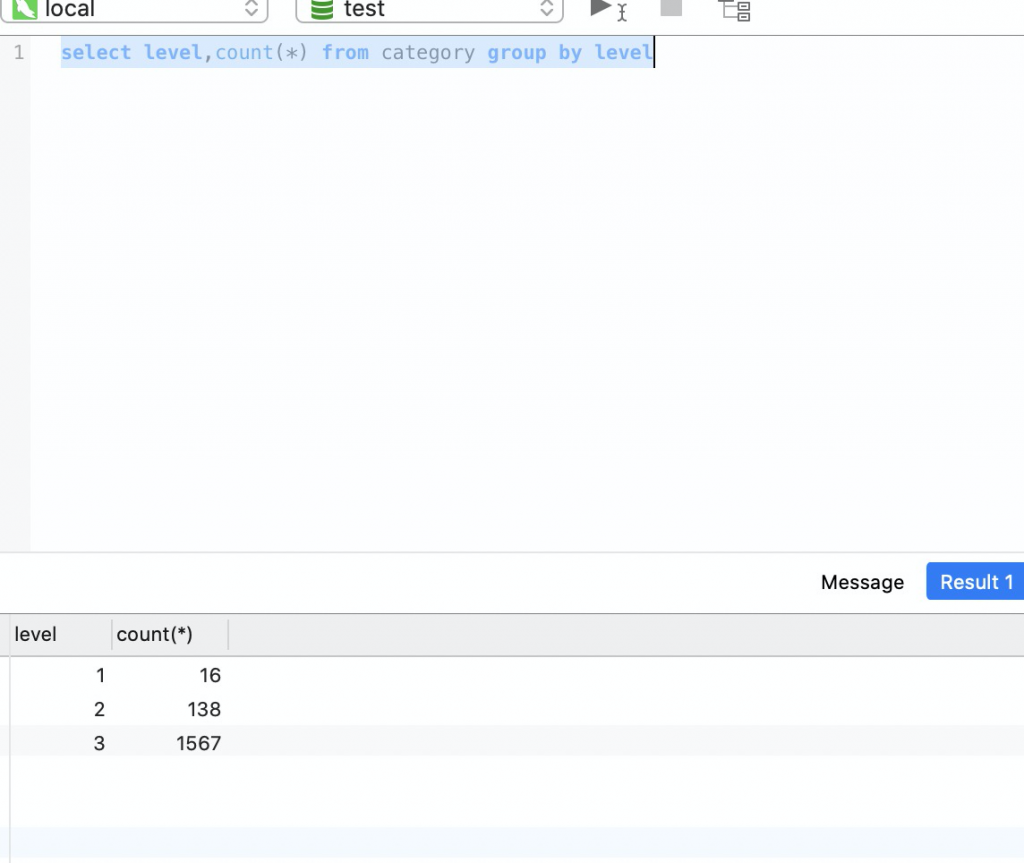
数据库结果如下:
注意点:
1、获取天猫首页元素的时候要对以及分类都悬浮一下,这样二级分类的元素才不会为空
2、注意编码,免得xpath解析失败