Python Scrapy爬虫
python最常用的爬虫框架Scrapy尝试
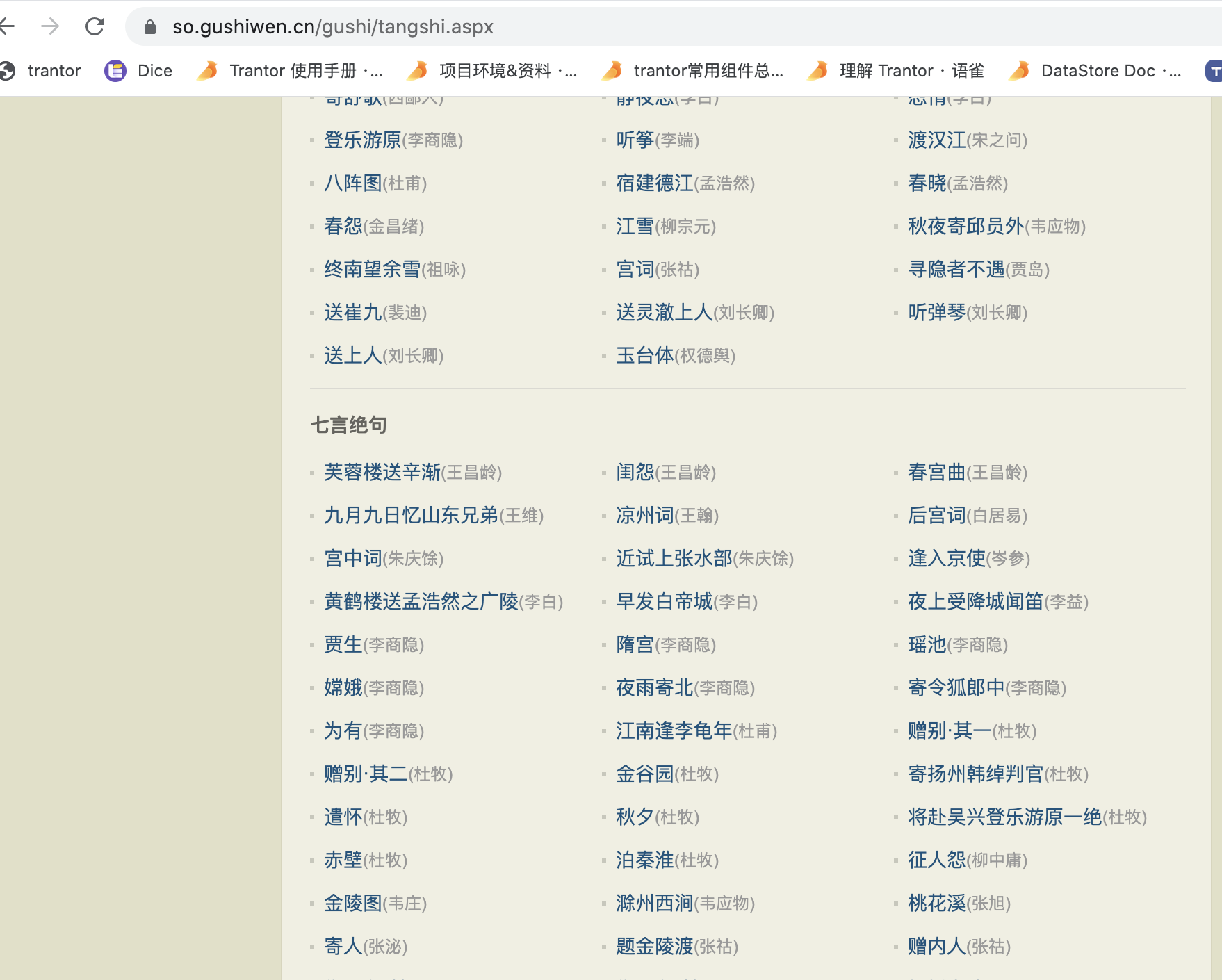
目标:下载这个页面的全部古诗
1、项目初始化
scrapy startproject scrapybaike
scrapy genspider baike gushiwen.cn
2、spider
先获取所有的诗词链接,再去详情页面获取古诗原文
import scrapy
from scrapybaike.items import ScrapybaikeItem
class BaikeSpider(scrapy.Spider):
name = 'baike'
allowed_domains = ['gushiwen.cn']
start_urls = ['https://so.gushiwen.cn/gushi/tangshi.aspx']
def parse(self, response):
urlList = response.xpath(
'//*[@id="html"]/body/div[2]/div[1]/div[2]/div[@class="typecont"]//span/a/@href').extract()
for url in urlList:
fullurl = response.urljoin(url)
yield scrapy.Request(url=fullurl, callback=self.parse_page)
def parse_page(self, response):
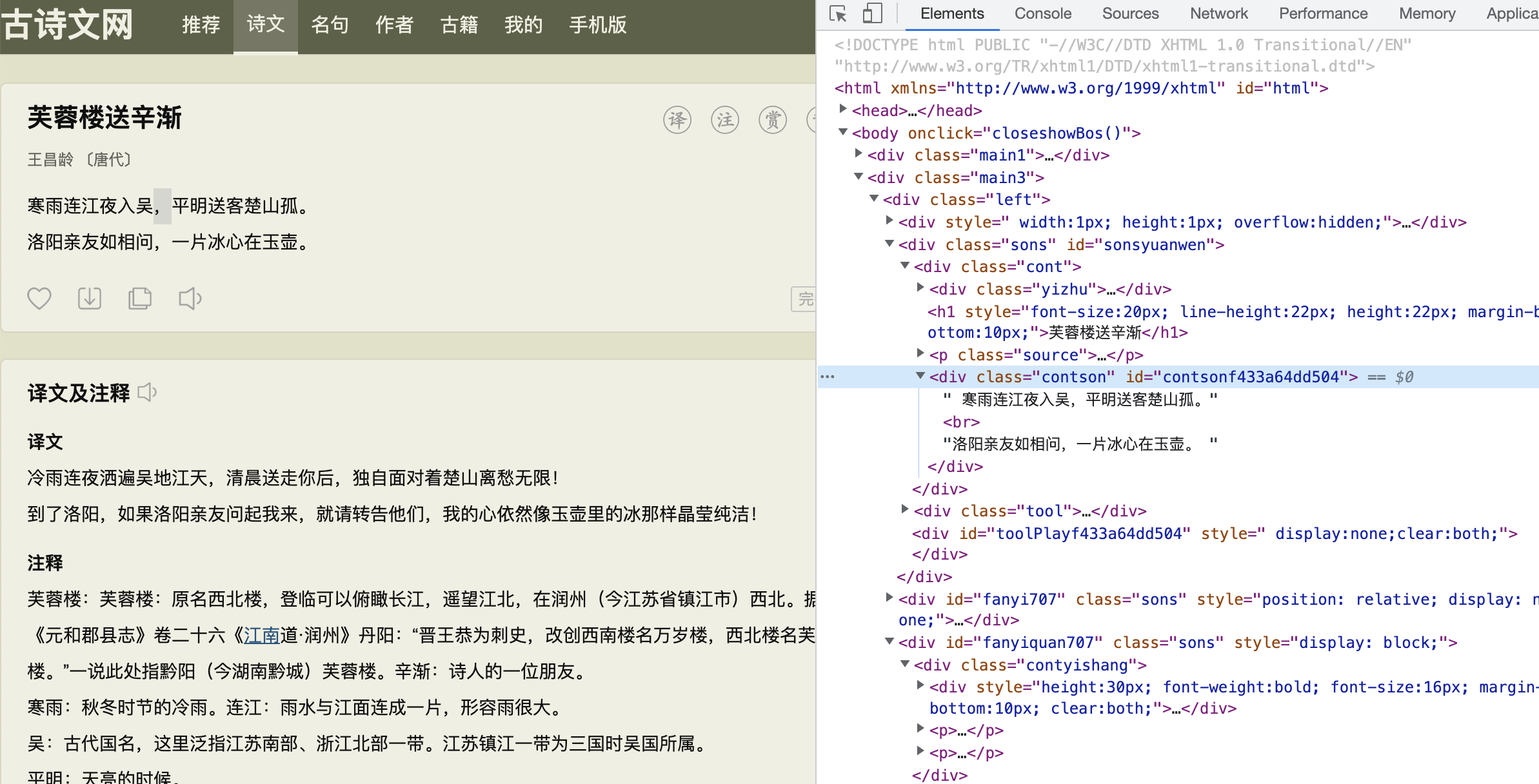
name = response.xpath('//*[@id="sonsyuanwen"]/div[1]/h1/text()').get()
author = response.xpath('//*[@id="sonsyuanwen"]/div[1]/p/a[1]/text()').get()
period = response.xpath('//*[@id="sonsyuanwen"]/div[1]/p/a[2]/text()').get()
content = response.xpath("string(/html/body/div[2]/div[1]/div[2]/div[1]/div[2])").get()
item = ScrapybaikeItem()
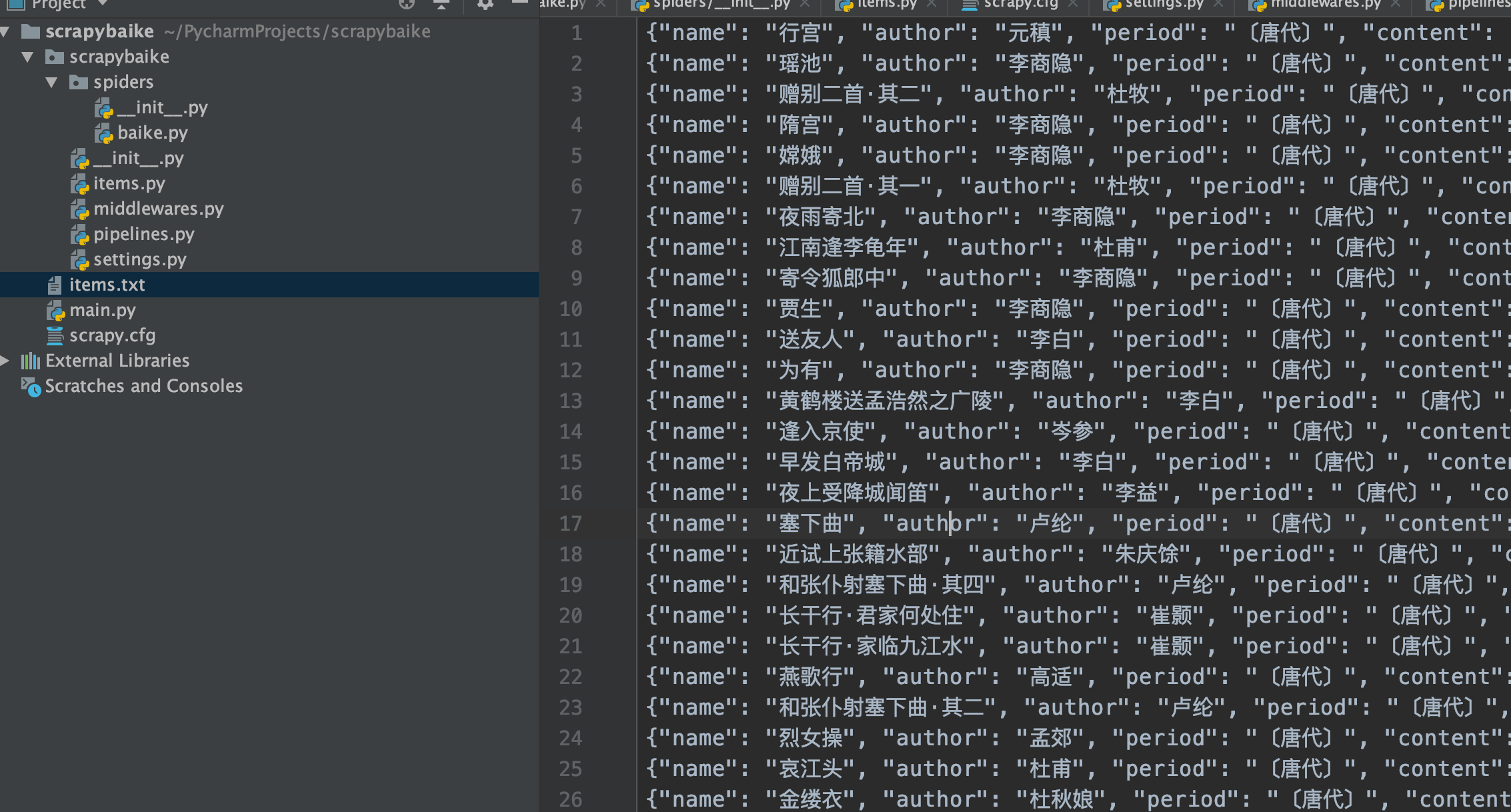
item['name'] = name
item['author'] = author
item['period'] = period
item['content'] = content
yield item
item 最终的对象
import scrapy
class ScrapybaikeItem(scrapy.Item):
name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
period = scrapy.Field()
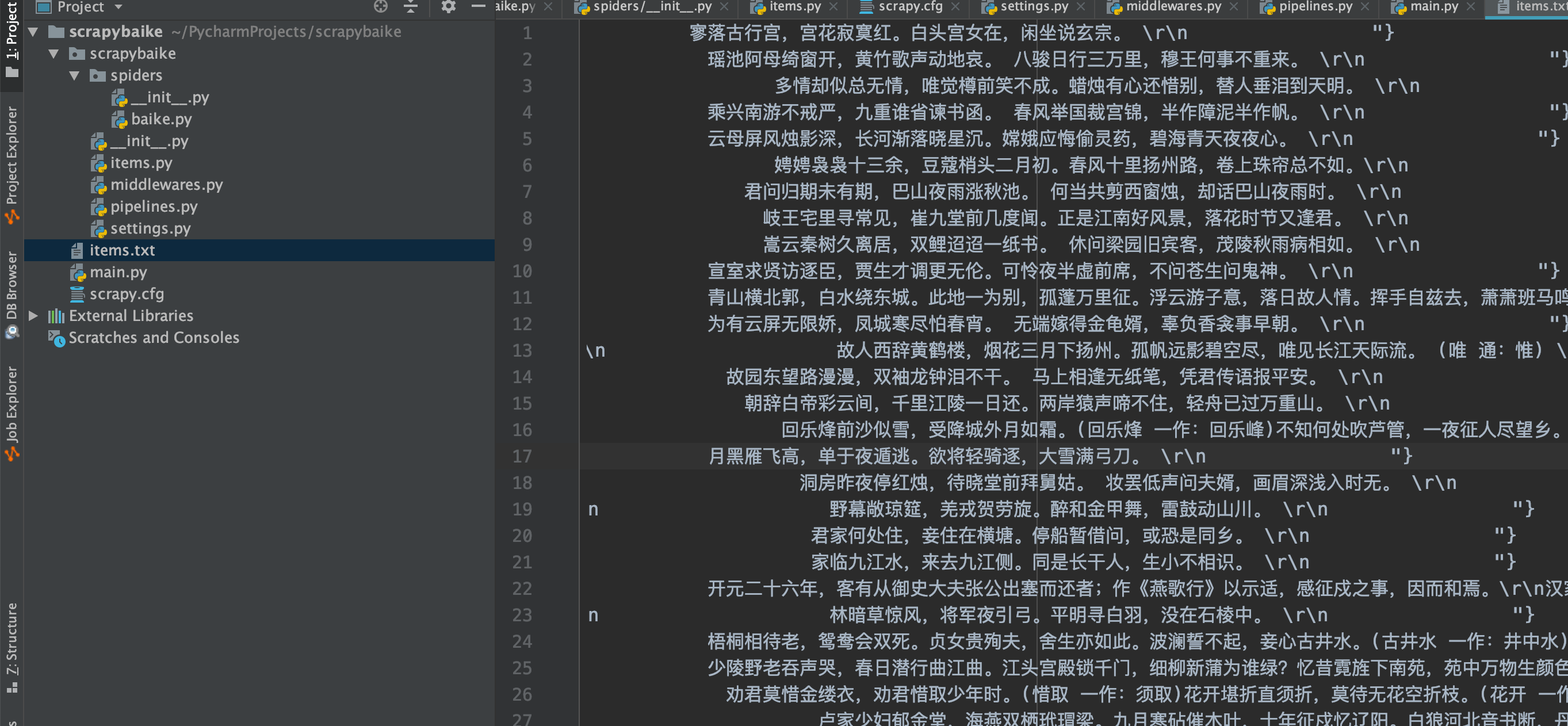
pipeline 将结果数据送入管道,存储到json文件中
import json
class ScrapybaikePipeline:
def __init__(self):
self.file = open('items.txt', 'w')
def process_item(self, item, spider):
line = json.dumps(dict(item),ensure_ascii=False) + "\n"
self.file.write(line)
return item
运行
import os
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy', 'crawl', 'baike'])
结果