Python Selenium天猫商品爬取(下)
1、上次已经对爬取的商品已经分类,分成一级、二级、三级类别,三级类别中有列表页面的链接
2、主要根据这个链接可以进入到列表主页面
3、由于暂时无法准确的分析出分页的关键,所以通过不断的跳转到下一页按钮的链接不断的获取后续的商品列表
4、每页60条商品 每个三级分类爬取50页
5、并在category表中增加status字段,对每个三级分类初始设置为start,每爬取完一个三级分类,设置status为end
根据下图元素分析出商品基本属性
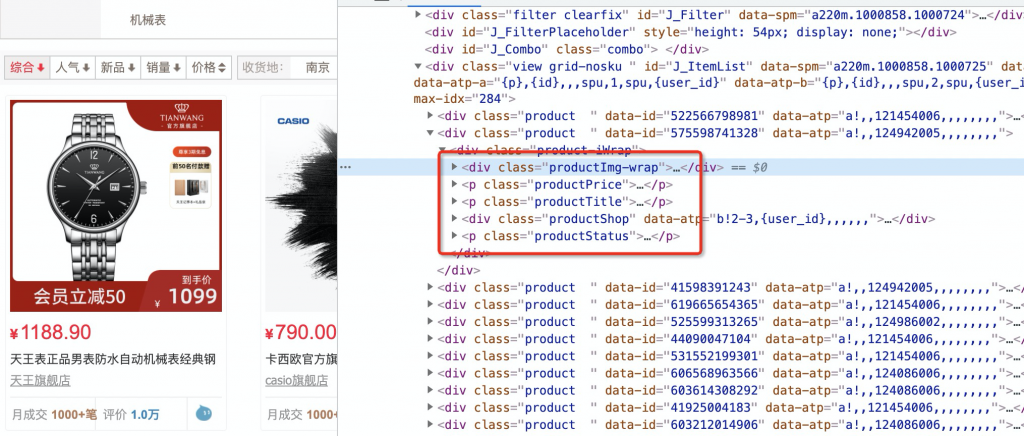
商品字段:
1、主图
2、标题
3、价格
4、商品详情链接
5、商家名称
6、商家链接
7、唯一id(有个data-id属性)
设想的流程是:
1、根据数据库中的分类表,循环对每个分类的商品url,进行解析,点击下一页,存储前50页的商品数据。
事实上是:
1、登录过程失败
本来按照理想的获取到文本框设置刚注册号的账号、密码以为会直接登录还是太年轻,天猫爸爸怎么会这么容易让你过呢,搜索相关文章,包括修改chromedriver的cdc标志位以及selenium设置开发模式,webdriver设置成undefined等等,几乎所有方法都试过了,全部失效,这些文章大部分都是2020年的,天猫爸爸已经升级了校验,没办法通过了,最后我选择的通过下载手机天猫app,用二维码扫描绕过登录,这个方法必须在脚本启动的过程中手动登录扫描,这样才行,也是没办法的办法的,可惜这样脚本只能在本地启动人工扫描登录,不能放在服务器上了。
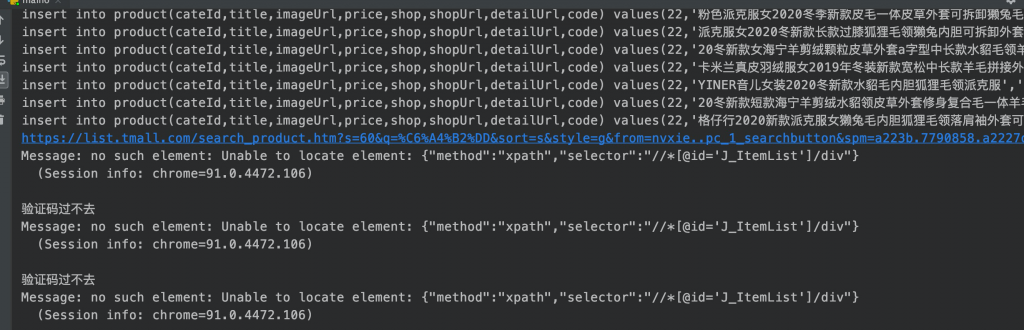
2、天猫拦截
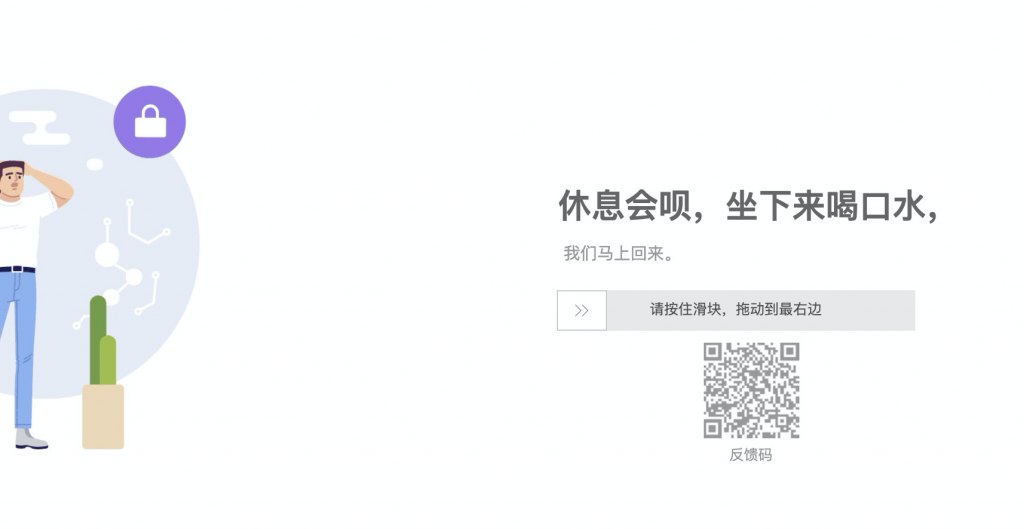
以为通过了登录这一关,天猫就会开放大门给你,可惜还是想太多,当我频繁爬取商品的时候,会出现如下页面。本着不放弃不抛弃的原则,再次使用selenium处理相关滑动条验证,重试多次,可惜这样是没用的,即便我手动处理滑动条验证,也都是没用的,好在等待一段时间,再试一下,还是可以成功进入的,可是这样的限制会导致根本无法大批量爬取。
3、主图问题
即便只能小批量的爬取点数据,这样都有坑,主图的链接不能完全获取成功,只有每页的前10个是正常的,其余的都获取失败,是默认的占位图,即便我使用滚动条,不断的滚动,可惜无论怎么样的滚动,就是获取不到。就这样 耗时几天的爬取 最终放弃,手动登录,爬取拦截等等问题让我放弃了继续爬取。
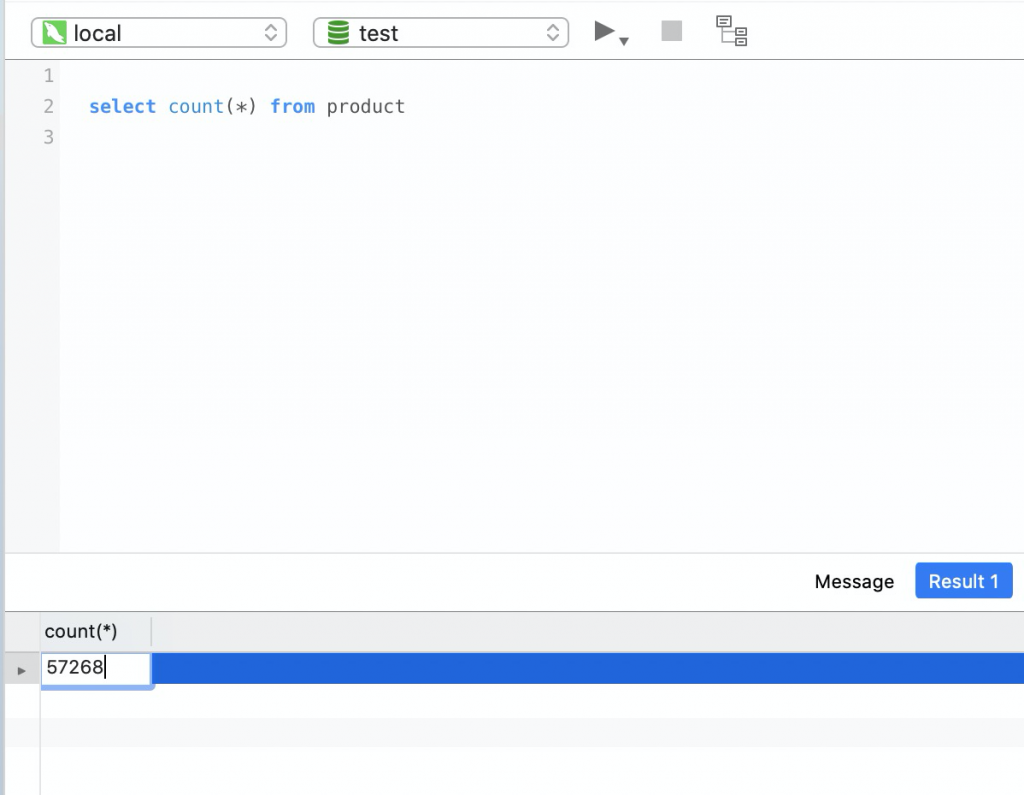
爬了一天最终结果如下,只是想尝试爬一下,没想到一道坎一道坎的,就这样结束吧。

核心代码如下:
# coding=utf-8
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
login_url = "https://tmall.com"
connect = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='XXXXXXX',
db='test',
charset='utf8'
)
cursor = connect.cursor()
#
chrome_option = webdriver.ChromeOptions()
# chrome_option.add_argument('--headless')
# chrome_option.add_argument('--disable-gpu')
chrome_option.add_experimental_option('excludeSwitches', ['enable-automation']) # 以开发者模式
browser = webdriver.Chrome(options=chrome_option)
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
def getContent(index, type):
prefix = "//*[@id='J_ItemList']/div["
prefix = prefix + str(index + 1)
prefix = prefix + "]"
if type == "image":
prefix = prefix + "/div[1]/div[1]/a/img"
return browser.find_element_by_xpath(prefix).get_attribute("src")
elif type == "title":
prefix = prefix + "/div[1]/p[2]/a"
return browser.find_element_by_xpath(prefix).text
elif type == "price":
prefix = prefix + "/div[1]/p[1]/em"
return browser.find_element_by_xpath(prefix).get_attribute("title")
elif type == "shop":
prefix = prefix + "/div[1]/div[3]/a"
return browser.find_element_by_xpath(prefix).text
elif type == "shopurl":
prefix = prefix + "/div[1]/div[3]/a"
return browser.find_element_by_xpath(prefix).get_attribute("href")
elif type == "data-id":
return browser.find_element_by_xpath(prefix).get_attribute("data-id")
elif type == "detailurl":
prefix = prefix + "/div[1]/p[2]/a"
return browser.find_element_by_xpath(prefix).get_attribute("href")
return None
def getProduct(index, cateId):
try:
item = {}
item['imageUrl'] = getContent(index, 'image')
item['title'] = getContent(index, 'title')
item['price'] = getContent(index, 'price')
item['shop'] = getContent(index, 'shop')
item['shopUrl'] = getContent(index, 'shopurl')
item['detailUrl'] = getContent(index, 'detailurl')
item['id'] = getContent(index, 'data-id')
item['cateId'] = cateId
return item
except Exception as e:
print(e)
return None
def insert(item):
try:
sql = "insert into product(cateId,title,imageUrl,price,shop,shopUrl,detailUrl,code) values(%d,'%s','%s','%s','%s','%s','%s','%s')"
sql = sql % (
int(item['cateId']), str(item['title']), str(item['imageUrl']), str(item['price']), str(item['shop']),
str(item['shopUrl']),
str(item['detailUrl']), str(item['id']))
cursor.execute(sql)
print(sql)
connect.commit()
except Exception as e:
print(e)
pass
def check(nextUrl):
count = 0
while count < 5:
try:
# 拖动滑块
time.sleep(2)
slider = browser.find_element_by_xpath("//*[@id='nc_1_n1z']")
slider_area = browser.find_element_by_xpath("//*[@id='nc_1__scale_text']/span")
ActionChains(browser).drag_and_drop_by_offset(slider, slider_area.size['width'],
slider.size['height']).perform()
time.sleep(2)
browser.get(nextUrl)
time.sleep(2)
items = browser.find_element_by_xpath("//*[@id='J_ItemList']/div")
return True
except Exception as e:
print("验证码过不去")
print(e)
count = count + 1
time.sleep(120)
count = 0
while count < 5:
try:
# 拖动滑块
time.sleep(2)
slider = browser.find_element_by_xpath("//*[@id='nc_1_n1z']")
slider_area = browser.find_element_by_xpath("//*[@id='nc_1__scale_text']/span")
ActionChains(browser).drag_and_drop_by_offset(slider, slider_area.size['width'],
slider.size['height']).perform()
time.sleep(2)
browser.get(nextUrl)
time.sleep(2)
items = browser.find_element_by_xpath("//*[@id='J_ItemList']/div")
return True
except Exception as e:
print("验证码过不去")
print(e)
count = count + 1
return False
def queryOneCategory(main_id, main_url):
page = 0
nextUrl = main_url
browser.get(main_url)
while page < 50:
try:
# for p in range(1, 24):
# pox = 200 * p
# browser.execute_script('window.scrollTo(document.body.scrollWidth,' + str(pox) + ');')
# time.sleep(1)
items = browser.find_element_by_xpath("//*[@id='J_ItemList']/div")
except Exception as e:
print(e)
if not check(nextUrl):
break
else:
items = browser.find_element_by_xpath("//*[@id='J_ItemList']/div")
try:
for j in range(0, 60):
pp = getProduct(j, main_id)
if pp is not None:
insert(pp)
except Exception as e:
print("商品解析出问题了")
print(e)
try:
nextUrl = browser.find_element_by_css_selector(".ui-page-next").get_attribute("href")
print(nextUrl)
browser.get(nextUrl)
page = page + 1
except Exception as e:
print("找不到下一页了")
print(e)
if not check(nextUrl):
break
time.sleep(10)
if __name__ == "__main__":
browser.maximize_window()
browser.get(login_url)
time.sleep(20)
sql = "select id,url from category where status='start'"
cursor.execute(sql)
cateList = []
for row in cursor.fetchall():
item = {}
main_id = row[0]
main_url = row[1]
item['main_id'] = main_id
item['main_url'] = main_url
cateList.append(item)
for cate in cateList:
queryOneCategory(cate['main_id'], cate['main_url'])
sql = "update category set status='end' where id=%d"
sql = sql % (int(cate['main_id']),)
cursor.execute(sql)
connect.commit()